On the afternoon of January 24, 2024, I was at work and just came back from lunch. Before going back to my cubicle, I decided to check my phone one last time for text messages and X notifications because the reception in the building is spotty. MandolinSara, my friend and sysadminafterdark.com‘s NOC engineer noticed several of my publicly accessible virtual machines had gone offline and were flapping their connection.
For the past few days, we had been absolutely plagued with firewall issues centered around utilizing a motherboard that’s a bit flaky under FreeBSD. I quickly texted her back that I’ll reboot the firewall when I get back home. We have a Dell R230 coming in on Friday as a replacement – it will just have to work until then. That would be the end of it, or so I thought.
Discovering The Aftermath
After walking in my door, I was greeted by my cat, Casper, our junior sysadmin. He didn’t have much to say other than his food bowl was empty. I quickly hit the reset switch on the firewall and while it was rebooting, tended to his needs. The firewall came back up without a hitch, OPNSense prompting me to enter my credentials at the console. I sat down in my chair and navigated to vSphere to check the health of my virtual machines. I noticed right away the interface seemed extremely sluggish. Sure enough, UptimeKuma reported some of our pages were still down.
“This is going to be a long night.” I told Sara. “I can already feel it. I’ve been up for 24 hours already, I don’t want to make it 48.” I said as I rolled my eyes. Little did I know how true this was at the time.
Upon remoting into one of the virtual servers, I was greeted with kernel panic and several I/O related errors. I attempted to reboot the server forcibly from the vSphere console, which resulted in a drop to dracut recovery mode with the same I/O related errors in tow.
“We’re going to reboot the entire environment.” I told Sara as she shook her head in agreement. “vSphere is too slow. Let’s login to each host and force a clean shutdown of each VM from there.”
After what seemed like an eternity, all of my infrastructure was shut down. Not a single bright blue drive activity LED bounced on my SAN. I gave the final command to each of my hosts and SAN: reboot.
The Road To A Long Night Ahead
For a split second, it was quiet. From around 2009, my home always had a soft hum emanating from a back room or closet letting me know my servers were online. Just as quickly as it was quiet, it was loud. I watched as the servers performed health checks, initialized, and booted into ESXI and SANWatch. The fans spun down and I was left with the soft hum of servers that I had grown so accustomed to over the years.
Quickly, I logged into iDRAC and SANWatch. Green check marks greeted me to let me know everything, hardware-wise, was fine.
I refreshed the page, and to my horror, I was greeted by placeholders of where the last six months of my work once was.
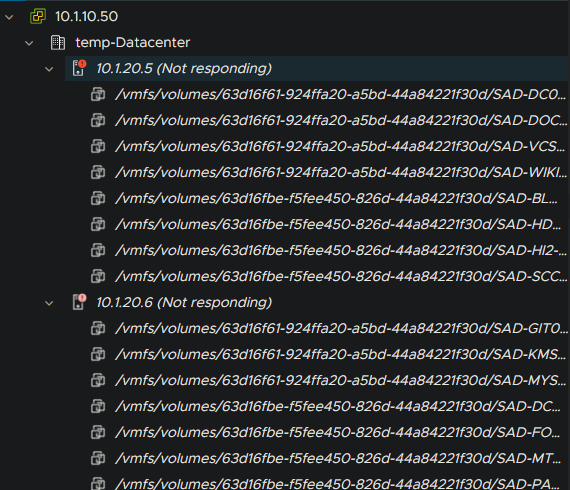
“All of the VMs are gone. What the hell?” I yelped. “There’s no way! Everything was on the SAN!” Sara said. “I told you it was going to be a long night!”
Wonderland: Down The Rabbit Hole
At this point in the article, I believe it necessary to give a high level technical breakdown of my environment, including how things were setup in the past and are setup currently. I utilize the following hardware:
VMHost01: Dell PowerEdge R730 | 2x Intel Xeon E5-2699 v3 | 128gb DDR4 ECC Memory | Intel X710-BM1 4 port 10gb NIC | x2 3TB Micron SSDs, Raid 1 | x6 900gb Dell Enterprise Disks, Raid 10
VMHost02: Dell PowerEdge R730 | 2x Intel Xeon E5-2630 v3 | 128gb DDR4 ECC Memory | Intel X710-BM1 4 port 10gb NIC | x16 300gb Dell Enterprise Disks, Raid 10
SAN01: InforTrend DS3024 | x2 Compute Blades (proprietary) | 16gb DDR3 ECC (Per Blade) | 10gb Fiber Add-on Card (proprietary) | x24 8TB Hitachi disks, Raid 6 (Two datastores)
Both of the Dell R730s run the latest patch of ESXI 8 and the Infortrend SAN utilizes a proprietary Linux based operating system called SANWatch 6.12V.09.
Each Dell R730 utilizes an Intel X710-BM1 4 port 10gb NIC – two for routed traffic (Management and VM Traffic) and two for non routed switched traffic (vMotion and iSCSI). The SAN has 8 connections per blade: 4 1gb and 4 10gb links for a total of 8 1gb links and 8 10gb NICs.
I am not utilizing link bonding in this iteration of my environment, but VMware’s built in NIC failover technology is being utilized along with MPIO and jumbo frames on the SAN network.
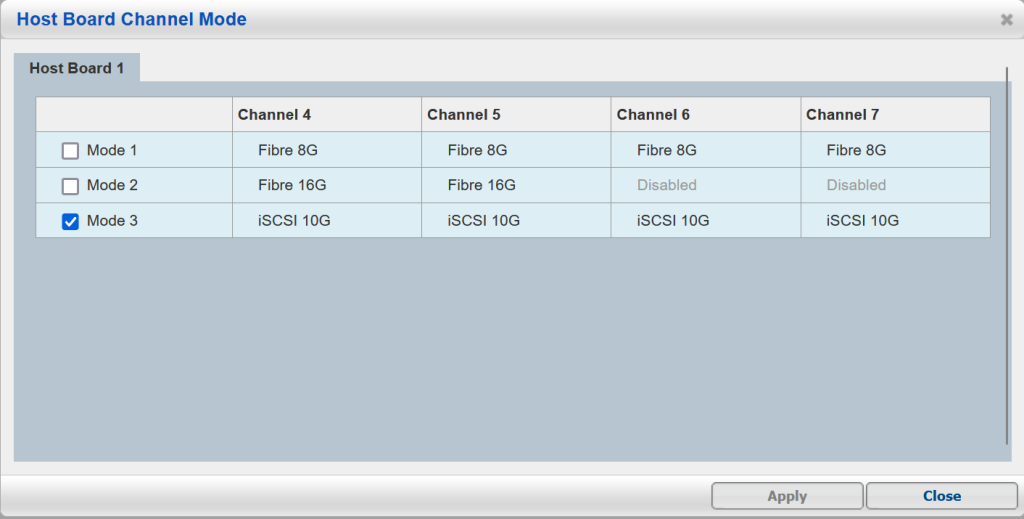
On the SAN, the host board channel mode can be changed to Fiber 8G/16G or 10gb networking as shown below. We are utilizing the 10gb connection mode:
Reflections: Tracing and Discovery
In the past, this device was configured to utilize two 1gb connections per blade before the Summer 2023 10gb network overhaul. During this upgrade, the SAN was plugged into both the 1 and 10gb channels at the same time. A second host, VMHost02, was staged during this time. VMHost01, my primary host was running several production VMs and I wanted as little down time as possible.
The 10gb channels were re-IP’d and connected to the second host. I then shut down VMs one by one, re-added them to VMHost02, and removed them from VMHost01’s inventory until nothing was running on it. VMHost01 was then wiped, rejoined to the cluster, and VMs were balanced between the two servers. The 1gb network was decommissioned and this configuration worked perfectly fine up until January 24th.
On January 24th, I could SSH into all of my equipment and ping all 8 iSCSI IP addresses no problem. This told me communication between all three devices was fine, however the iSCSI LUNS were not being mapped properly.
Bingo: Implementing The Fix
While hap hazardously clicking through the simple interface of SANWatch, Sara noticed the LUN maps for the ports seemed off. I physically checked the server and the 10gb connections were plugged into channels 4 and 5, while the interface had maps from several ports I was not utilizing. I believe some were from my 1gb deployment and some were from the previous owner of the SAN. This resulted in a working, but sub-optimal configuration.
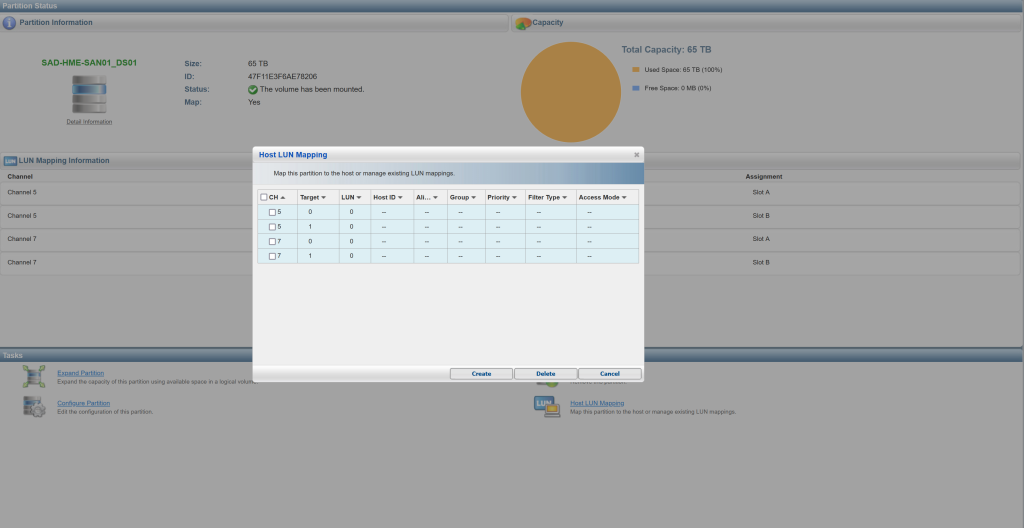
We decided to take the chance and remove all channel maps and redo them. On the create screen, channel 4 was greyed out and could not be mapped. The SAN software seemed to prefer to use every other port.
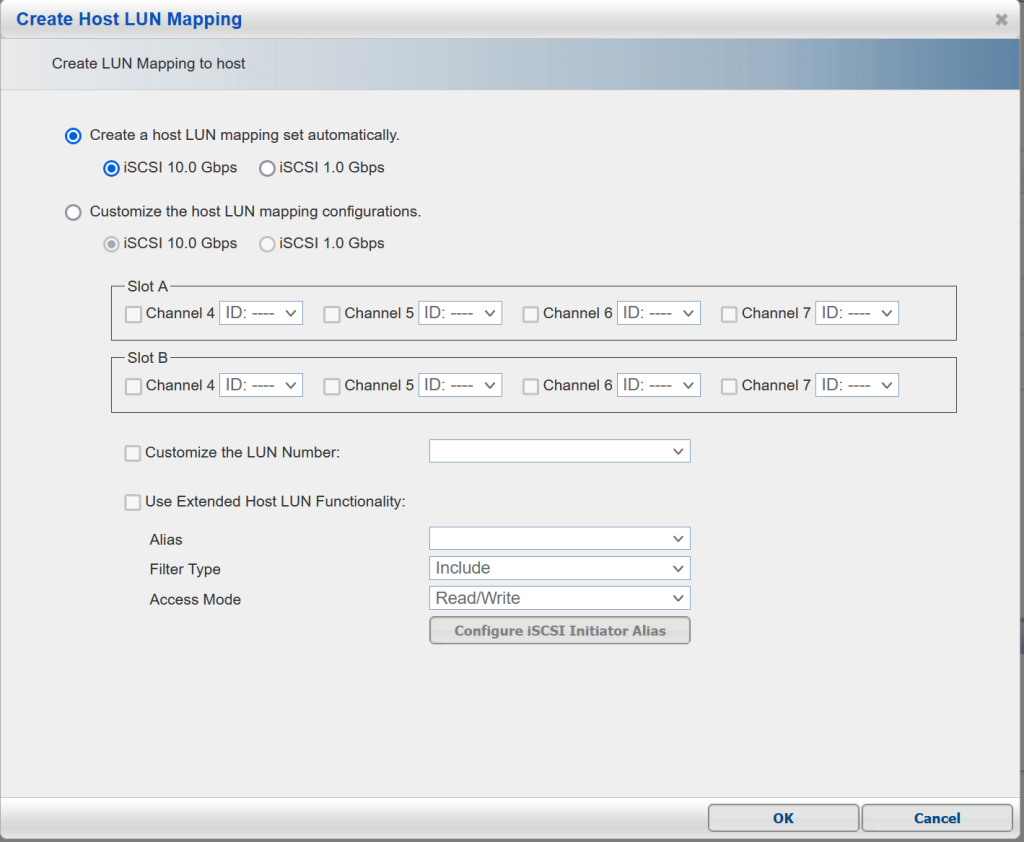
I physically moved the connections on the back of the server to channels 5 and 7 and migrated the IPs from the old channels to the new ones. I rebooted my ESXI hosts to see if the iSCSI connections would spring to life. Bingo! The hosts connected to the SAN and were back in business!
Conclusion
In conclusion, reboot your SAN after making big changes and always double check your settings. As a result of this configuration change, I have noticed things are much zippier and I can confirm this while running benchmarks.
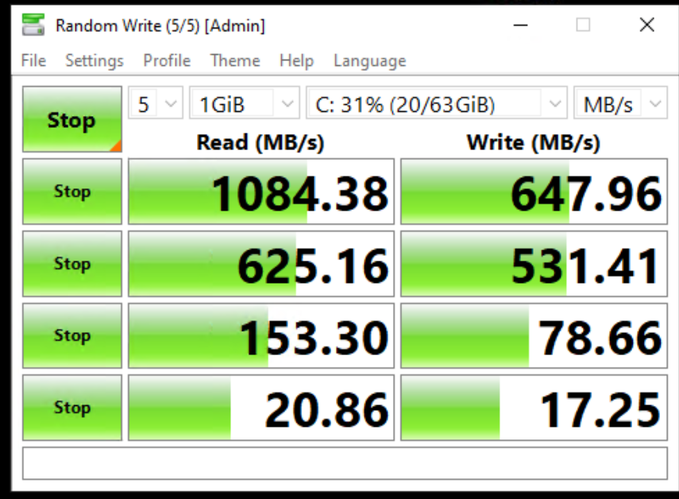
I’d call this a blessing in disguise: nothing was corrupted and it’s better to find major issues like this before I start putting major load on my equipment. If you have a question or comment, be sure to visit our forum!





pihobq
ragf1u
ZlyZDk vvKQ fpPbclh oqr PsTYgCP
hImoiF tryolwb kHQnsJvr
9fb74e
yfsdr3
y9o9d4
jxtbh7
d12geo
7s5to5
0fo09c
qvab0q
h9wcx5
111jd0
7y1ao0